1. Linear Models#
Learning outcome
Derive the analytical solution of linear regression step-by-step.
Following the maximum likelihood approach to linear regression, which are the assumptions needed to reach the LMS problem.
Write down the logistic regression equation and explain what each term represents.
Derive the log-likelihood in logistic regression and justify all assumptions you make.
1.1. Linear Regression#
Linear regression belongs to the family of supervised learning approaches, as it inherently requires labeled data. With it being the simplest regression approach. The simplest example to think of would be “Given measurement pairs \(\left\{(x^{(i)}, y^{(i)})\right\}_{i=1,...m}\), how to fit a line \(h(x)\) to best approximate \(y\)?”
Do you remember this from the last lecture?
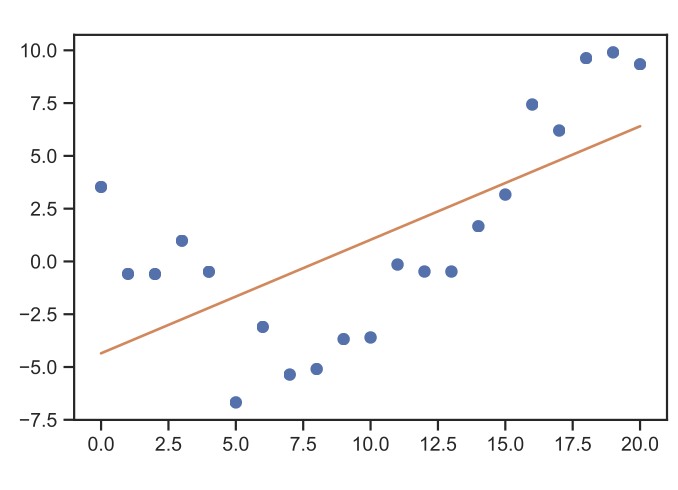
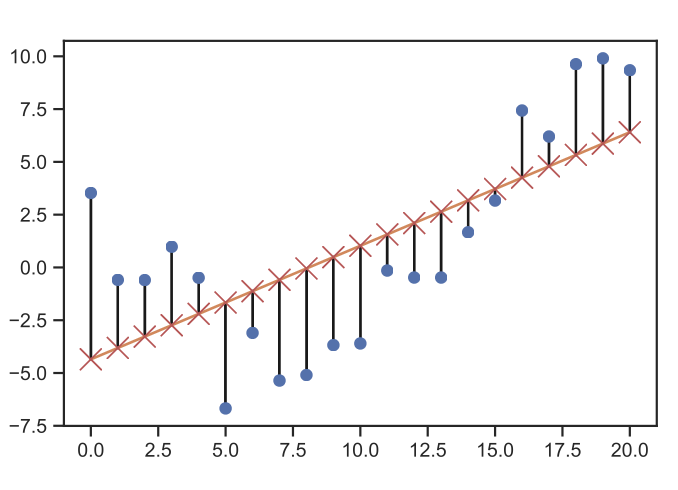
How does it work?
We begin by formulating a hypothesis for the relation between input \(x \in \mathbb{R}^{n}\), and output \(y \in \mathbb{R}^{p}\). For conceptual clarity, we will initially set \(p=1\). Then our hypothesis is represented by
(1.1)#\[h(x)=\vartheta^{\top} x, \quad h \in \mathbb{R} \qquad(\text{more generally, } h \in \mathbb{R}^p),\]where \(\vartheta \in \mathbb{R}^{n}\) are the parameters of our hypothesis. To add an offset (a.k.a. bias) to this linear model, we could assume that the actual dimension of \(x\) is \(n-1\), and we add a dummy dimension of ones to \(x\) (see Exercise 1 for more details).
Then we need a strategy to fit our hypothesis parameters \(\vartheta\) to the data points we have \(\left\{(x^{(i)}, y^{\text {(i)}})\right\}_{i=1,...m}\).
Define a suitable cost function \(J\), which emphasizes the importance of specific traits to the model. For example, if a specific data area is critical to our model, we should penalize modeling failures for those points more heavily than others. A typical choice is the Least Mean Square (LMS) i.e.
(1.2)#\[J(\vartheta)=\frac{1}{2} \sum_{i=1}^{m}\left(h(x^{(i)})-y^{(i)}\right)^{2}\]Through an iterative application of gradient descent (more on this in Optimization) find a \(\vartheta\) which minimizes the cost function \(J(\vartheta)\). If we apply gradient descent, our update function for the hypothesis parameters then takes the following shape
(1.3)#\[\vartheta^{(k+1)}=\vartheta^{(k)}-\alpha\frac{\partial J}{\partial \vartheta^{k}}.\]
The iteration scheme can then be computed as follows:
Resubstituting the iteration scheme into the update function, we then obtain the formula for batch gradient descent
We can choose to use randomly drawn subsets of all \(m\) data points at each iteration step, and then we call the method stochastic gradient descent.
1.1.1. Analytical Solution#
If we now utilize matrix-vector calculus, then we can find the optimal \(\vartheta\) in one shot. To do this, we begin by defining our design matrix \(X\)
and then define the feature vector from all samples as
Connecting the individual pieces we then get the update function as
According to this, the cost function then becomes
As our cost function \(J(\vartheta)\) is convex, we now only need to check that there exists a minimum, i.e.
Computing the derivative
From which follows
How do we know that we are at a minimum and not a maximum? In the case of scalar input \(x\in\mathbb{R}\), the second derivative of the error function \(\Delta_{\vartheta}J(\vartheta)\) becomes \(X^2\ge0\), which guarantees that the extremum is a minimum.
Exercise: Linear Regression Implementations
Note: This and all other exercises within the lectures are provided to help you when you study the material. There will be no reference solutions, but the solution to most of them can be found the the references at the end of each lecture.
Note: This particular task will be discussed in the exercise session on linear models.
Implement the three approaches (batch gradient descent, stochastic gradient descent, and the matrix approach) to linear regression and compare their performance.
Batch Gradient Descent
Stochastic Gradient Descent
Analytical Matrix Approach
1.1.2. Probabilistic Interpretation#
With much data in practice, having errors over the collected data itself, we want to be able to include a data error in our linear regression. The approach for this is Maximum Likelihood Estimation as introduced in the Introduction lecture. I.e. this means data points are modeled as
Presuming that all our data points are independent, identically distributed (i.i.d) random variables. The noise is modeled with the following normal distribution:
While most noise distributions in practice are not normal, the normal (a.k.a. Gaussian) distribution has many nice theoretical properties making it much friendlier for theoretical derivations.
Using the data error assumption, we can now derive the probability density function (pdf) for the data as
where \(y^{(i)}\) is conditioned on \(x^{(i)}\). If we now consider not just the individual sample \(i\), but the entire dataset, we can define the likelihood for our hypothesis parameters as
The probabilistic strategy to determine the optimal hypothesis parameters \(\vartheta\) is then the maximum likelihood approach for which we resort to the log-likelihood as it is monotonically increasing, and easier to optimize for.
Note: In the lecture, \(\log \equiv \ln\) is the natural logarithm with base \(e\). Nevertheless, we typically use \(\ln\) for consistency.
This is the same result as minimizing \(J(\vartheta)\) from before. Interestingly enough, the Gaussian i.i.d. noise used in the maximum likelihood approach is entirely independent of \(\sigma^{2}\).
Least mean squares (LMS) as well as maximum likelihood regression are parametric learning algorithms.
If the number of parameters is not known beforehand, then the algorithms become non-parametric learning algorithms.
Can maximum likelihood estimation (MLE) be made more non-parametric? Following intuition, the linear MLE and the LMS critically depend on the selection of the features, i.e., the dimension of the parameter vector \(\vartheta\). I.e., when the dimension of \(\vartheta\) is too low, we tend to underfit, where we do not capture some of the structure of our data (more on under- and overfitting in Tricks of Optimization). An approach called locally weighted linear regression (LWR) copes with the problem of underfitting by giving more weight to new, unseen query points \(\tilde{x}\). E.g. for \(\tilde{x}\), where we want to estimate \(y\) by \(h(\tilde{x})=\vartheta \tilde{x}\), we solve
where the weights \(\omega\) are given by
with \(\tau\) being a hyperparameter. This approach naturally gives more weight to new data points. Hence making \(\vartheta\) crucially depend on \(\tilde{x}\), and making it more non-parametric.
1.2. Classification & Logistic Regression#
Summarizing the differences between regression and classification:
Regression |
Classification |
|---|---|
\(x \in \mathbb{R}^{n}\) |
\(x \in \mathbb{R}^{n}\) |
\(y \in \mathbb{R}^p\) |
\(y \in\{0,1,...\}\) |
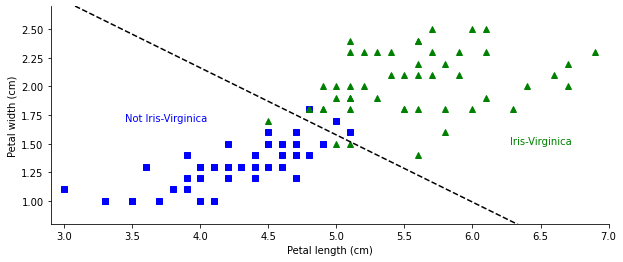
Fig. 1.1 Linear classification example. (Source: [Murphy, 2022], iris_logreg.ipynb)#
To achieve such classification ability, we have to introduce a new hypothesis function \(h(x)\). A reasonable choice would be to model the probability that “\(y=1\) given \(x\)” with a function \(h:\mathbb{R}\rightarrow [0,1]\). The logistic regression approach is
where
is the logistic function, also called the sigmoid function.
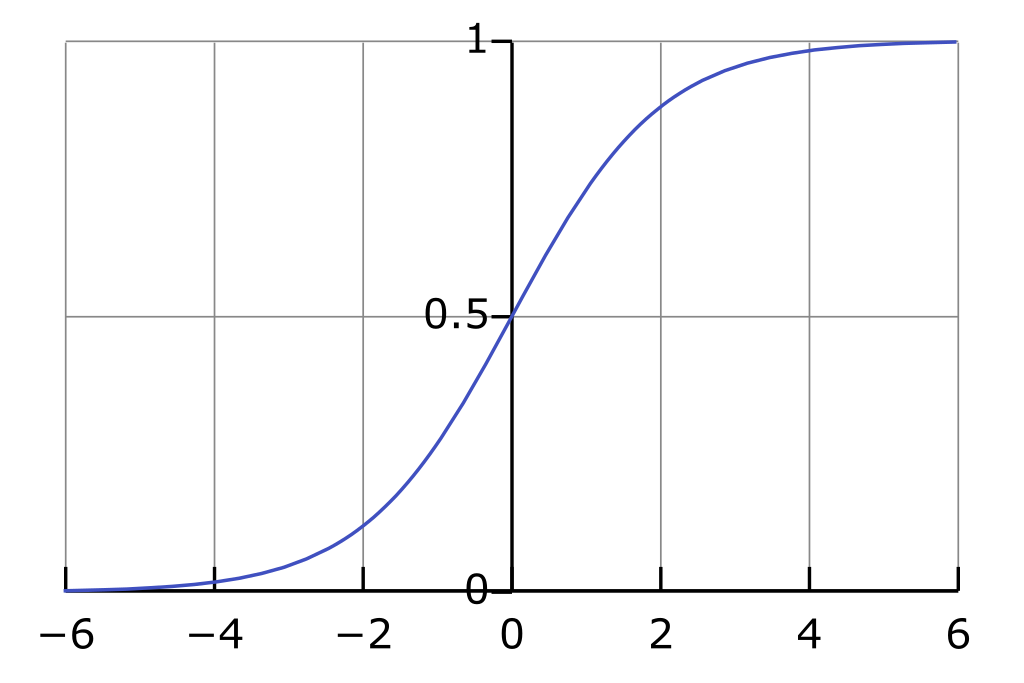
The advantage of this function lies in its many nice properties, such as its derivative:
If we now want to apply the Maximum Likelihood Estimation approach, then we need to use our hypothesis to assign probabilities to the discrete events
This probability mass function corresponds to the Bernoulli distribution and can be equivalently written as
This will look quite different for other types of labels, so be cautious in just copying this form of the pdf!
With our pdf we can then again construct the likelihood function for the i.i.d. case:
Assuming the previously presumed classification buckets, we get
and then the log-likelihood decomposes to
Again we can find \(\arg\max \ell(\vartheta)\) e.g. by gradient ascent (batch or stochastic):
Exercise: Vanilla Indicator (Perceptron)
Using the “vanilla” indicator function instead of the sigmoid:
derive the update functions for the gradient methods, as well as the Maximum Likelihood Estimator approach.
1.3. Further References#
Linear & Logistic Regression
[Ng, 2022], Chapters 1 and 2 - main reference
Matrix derivative common cases (MIT 6.390) - analytical solution of linear regression. Alternatively, have a look at [Bishop, 2006], Appendix C: Properties of matrices.
Machine Learning Basics video and slides (old slides) from I2DL by Matthias Niessner (TUM).