6. Support Vector Machines#
Learning outcome
What are Lagrange multipliers in the context of constrained optimization?
Explain how the decision boundary of the maximum margin classifier depends on each data point. Illustrate your explanation with a drawing.
How does the kernel method allow us to separate otherwise not linearly separable data points?
When is a kernel valid?
Support Vector Machines are one of the most popular classic supervised learning algorithms. This lecture will first discuss the mathematical formalism of solving constrained optimization problems using Lagrange multipliers. We will then look at linear binary classification using the maximum margin and soft margin classifiers. Ultimately, we will present the kernel trick and how it extends the previous two approaches to non-linear boundaries within the more general Support Vector Machine.
6.1. The Constrained Optimization Problem#
We define a constrained optimization problem as
Here, \(\underset{\omega}{\min}\) seeks to find the minimum subject to the constraint(s) \(h_{i}(\omega)\). One possible way to solve this is to use Lagrange multipliers, for which we define the Lagrangian \(\mathcal{L}\), which takes the constraints into account.
The \(\beta_{i}\) are the Lagrangian multipliers, which need to be identified to find the constraint-satisfying \(\omega\). The necessary conditions to solve this problem are to solve
for \(\omega\) and \(\beta\). In classification problems, we do not only have equality constraints as above but can also encounter inequality constraints. We formulate the general primal optimization problem as:
To solve it, we define the generalized Lagrangian.
with the additional Lagrange multipliers \(\alpha_i\). Let us define the primal quantity
Now, we can verify that this optimization problem satisfies
Where does this case-by-case breakdown come from?
In the first case, the constraints are inactive and contribute nil to the sum.
In the second case, the sums increase linearly with \(\alpha_{i}\), \(\beta_{i}\) beyond all bounds.
That is, we recover the original primal problem with \(p^{\star}\) being the optimal value of the primal problem. With this, we can now formulate the dual optimization problem:
with \(\theta_{D}(\alpha, \beta) = \underset{\omega}{\min} \hspace{2pt} \mathcal{L}(\omega, \alpha, \beta)\) and \(d^{\star}\) the optimal value of the dual problem. Please note that the primal and dual problems are equivalent to exchanging the order of minimization and maximization. To show how these problems are related, we first derive a relation between min-max and max-min using \(\mu(y) = \underset{x}{\inf} \hspace{2pt} \kappa(x, y)\):
From the last line, we can immediately imply the relation between the primal and the dual problems.
where the inequality can, under certain conditions, turn into equality. The conditions for this to become equality are the following (going back to the Lagrangian form from above):
\(f\) and \(g_{i}\) are convex, i.e. their Hessians are positive semi-definite.
The \(h_{i}\) are affine, i.e., they can be expressed as linear functions of their arguments.
Under the above conditions, the following holds:
The optimal solution \(\omega^{\star}\) to the primal optimization problem exists.
The optimal solution \(\alpha^{\star}\), \(\beta^{\star}\) to the dual optimization problem exists.
\(p^{\star}=d^{\star}\).
\(\omega^{\star}\), \(\alpha^{\star}\), and \(\beta^{\star}\) satisfy the Karush-Kuhn-Tucker (KKT) conditions.
The KKT conditions are expressed as the following conditions:
Moreover, if a set \(\{\omega^{\star}\), \(\alpha^{\star}, \beta^{\star}\}\) satisfies the KKT conditions, then it is a solution to the primal/dual problem. The KKT conditions are sufficient and necessary here. The dual complementarity condition (KKT3) indicates whether the \(g_{i}(\omega) \leq 0\) constraint is active:
i.e., if \(\alpha_{i}^{\star} > 0\), then \(\omega^{\star}\) is “on the constraint boundary”.
6.2. Maximum Margin Classifier (MMC)#
Alternative names for Maximum Margin Classifier (MMC) are Hard Margin Classifier and Large Margin Classifier. This classifier assumes that the classes are linearly separable.
Now, we can (re-)introduce the linear discriminator. As we have seen, logistic regression \(p(y=1| x; \vartheta)\) is modeled by \(h(x) = g(\vartheta^{\top} x) = \text{sigmoid}(\vartheta^{\top} x)\):
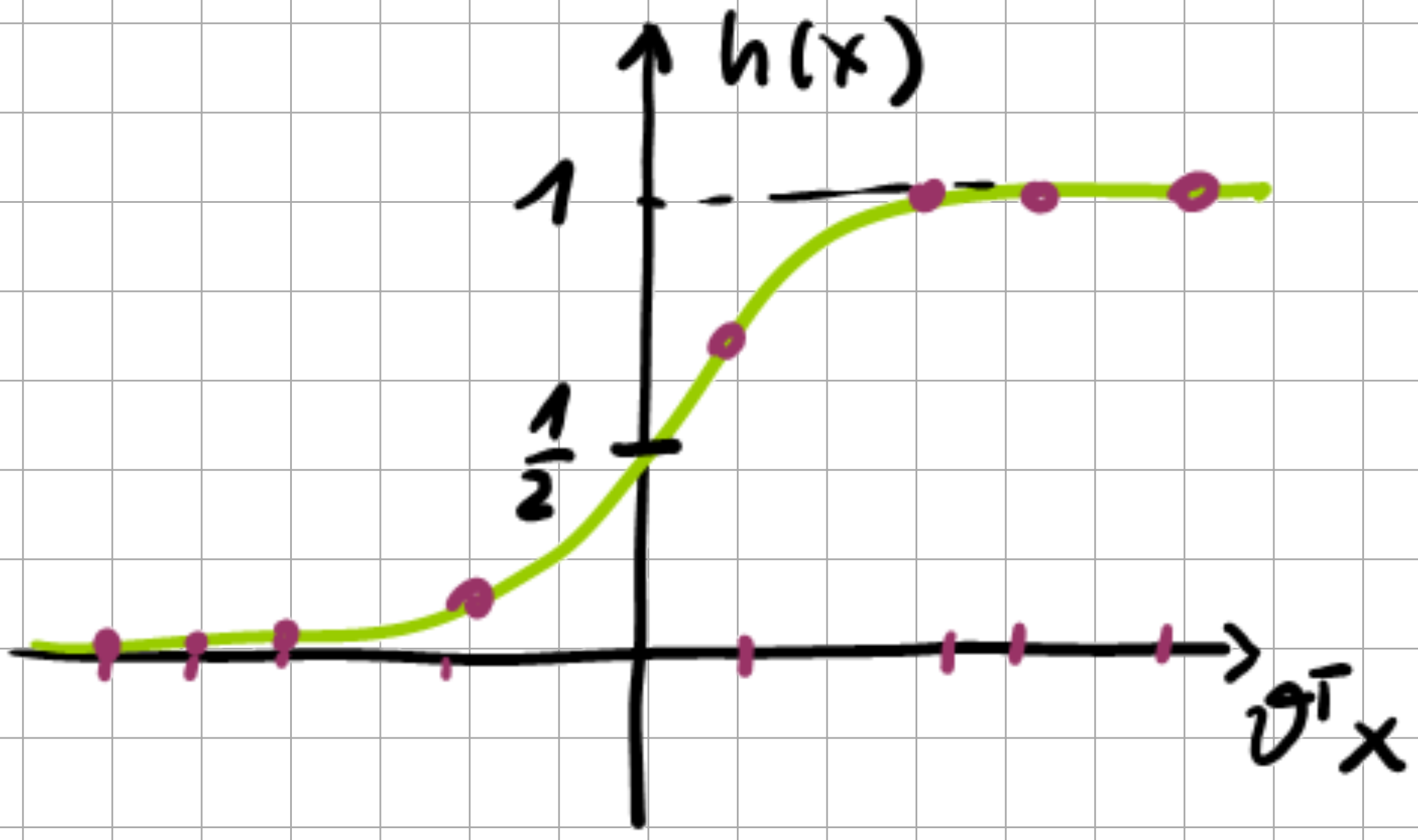
Fig. 6.1 Sigmoid function.#
If \(g(\vartheta^{\top} x)\) is close to one, then we have large confidence that \(x\) belongs to class \(\mathcal{C}_{1}\) with \(y=1\), whereas if it is close to \(\frac{1}{2}\), we have much less confidence:

Fig. 6.2 Confidence of logistic regression classifier.#
The intuition here is that we seek to find the model parameters \(\vartheta\) such that \(g(\vartheta^{\top}x)\) maximizes the distance from the decision boundary \(g(\vartheta^{\top}x) = \frac{1}{2}\) for all data points.
For consistency with the standard SVM notation, we slightly reformulate this problem setting:
where \(\omega^{\top} x + b\) defines a hyperplane for our linear classifier. With \(b\), we now make the bias explicit, as it was previously implicit in our expressions.
6.2.1. Functional Margin#
The functional margin of \((\omega, b)\) w.r.t. a single training sample is defined as
For a confident prediction, we would then like to have a maximum gap between the classes for a good classifier.
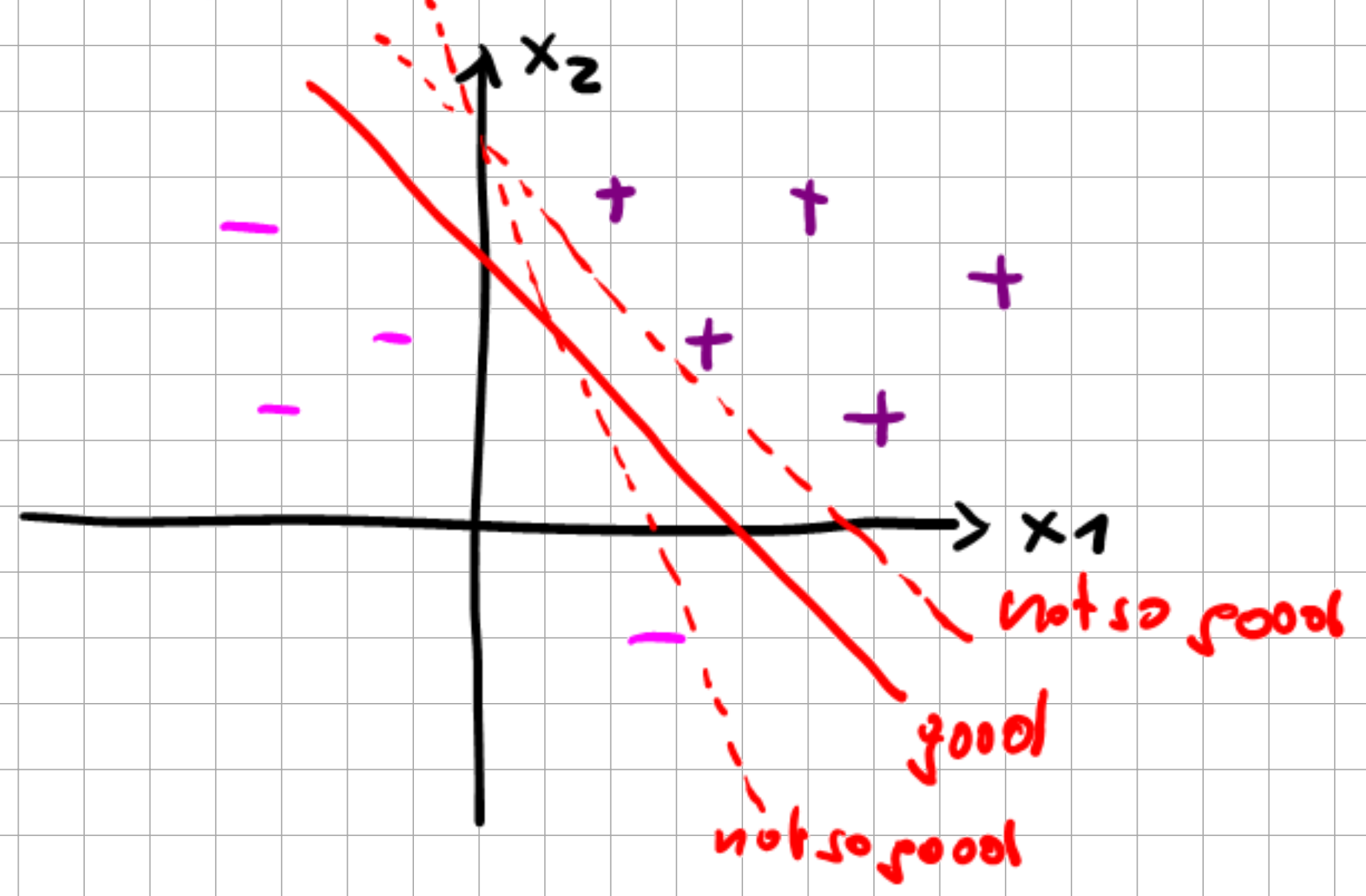
Fig. 6.3 Good vs bad linear decision boundary.#
For correctly classified samples, we always have
as \(g(\omega^{\top}x + b) = y = \pm 1 \). Note that the induced functional margin is invariant to scaling:
However, if we want to maximize this margin, we could do that without changing the actual decision boundary. Also, note that the classifier does not reflect that the margin is not invariant.
For the entire set of training samples, we define the functional margin as
6.2.2. Geometric Margin#
Now we can define the geometric margin with respect to a single sample \(\gamma^{(i)}\) as follows.
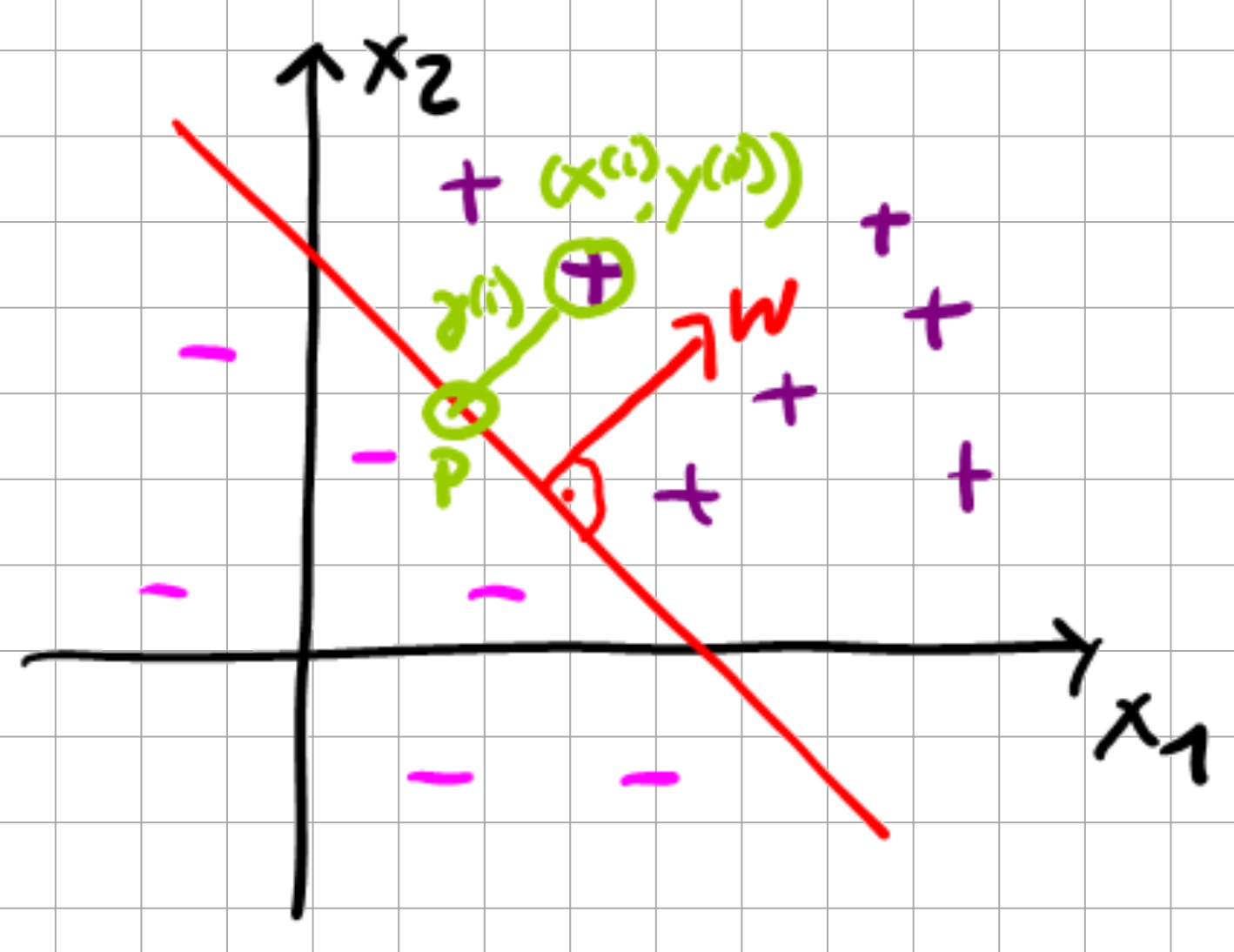
Fig. 6.4 The geometric margin.#
The distance \(\gamma^{(i)}\) of point \(x^{(i)}\) from the decision boundary, i.e., from the closest point P on that boundary, is given by
where \(x^{(i)} - \gamma^{(i)} \frac{\omega}{||\omega||}\) gives the location of the point P, and \(\frac{\omega}{||\omega||}\) is the unit normal. As P is a member of the decision boundary, no matter where it is placed on the boundary, the equality always has to be zero by definition.
As this was for an example on the \(+\) side, we can generalize said expression to obtain
Please note that the geometric margin indeed is scale invariant. Also, note that for \(|| \omega ||=1\) the functional and geometric margin are the same. For the entire set of samples, we can then define the geometric margin as:
6.2.3. Maximum Margin Classifier#
With these mathematical tools, we are now ready to derive the Support Vector Machine (SVM) for linearly separable sets (a.k.a. Maximum Margin Classifier) by maximizing the previously derived geometric margin:
However, in this formulation, the second constraint \(||\omega|| = 1\) is non-convex, which is inefficient to solve numerically. Thus, we formulate a slightly different optimization problem that again seeks to maximize the geometric margin:
where we applied the definition of \(\gamma = \frac{\hat{\gamma}}{||\omega||}\). Although we eliminated the previous non-convex constraint, we suffered a setback in the process as we now have a non-convex objective function. In a third attempt to formulate an optimization problem, using that the geometric margin \(\gamma\) is scale-invariant, we can now simply scale \(||\omega||\) such that \(\hat{\gamma} = \gamma ||\omega|| = 1\). Given \(\hat{\gamma} = 1\) it is clear that
s.t. the constraints are satisfied. This is now a convex objective with linear constraints.
The Support Vector Machine is generated by the primal optimization problem.
or alternatively
Upon checking with the KKT dual complementarity condition, we see that \(\alpha_{i} > 0\) only for samples with \(\gamma_{i}=1\), i.e.
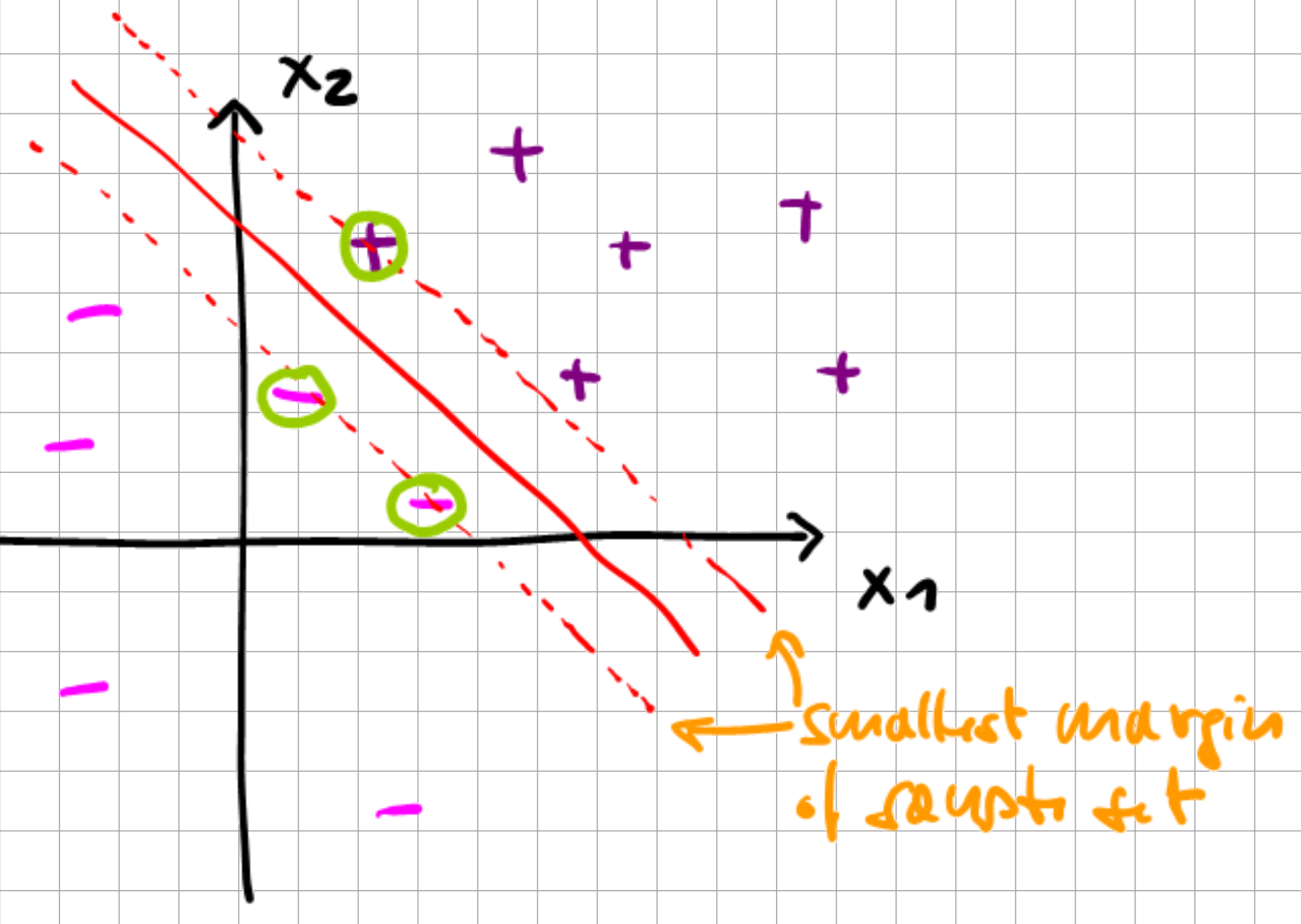
Fig. 6.5 Maximum Margin Classifier.#
The three samples “-”, “-”, and “+” in the sketch are the only ones for which the KKT constraint is active.
These are called the support vectors.
From the sketch, we can already ascertain that the number of support vectors may be significantly smaller than the number of samples, i.e., the number of active constraints that we have to take into account. Next, we construct the Lagrangian of the optimization problem:
Note that in this case, our Lagrangian only has inequality constraints!
We can then formulate the dual problem \(\theta_{D}(\alpha) = \underset{\omega, b}{\min} \hspace{2pt} \mathcal{L}(\omega, b, \alpha)\) and solve for \(\omega\) and \(b\) by setting the derivatives to zero.
The \(\omega\) we can then resubstitute into the original Lagrangian (Eq. (6.28)) to get the term
If we plug that into the Lagrangian (Eq. (6.28)), we get the dual
which we can then optimize as an optimization problem
The first constraint in this optimization problem singles out the support vectors, whereas the second constraint derives itself from our derivation of the dual of the Lagrangian (see above). The KKT conditions are then also satisfied.
The first KKT condition is satisfied as of our first step in the conversion to the Lagrangian dual.
The second KKT condition is not relevant.
The third KKT condition is satisfied with \(\alpha_{i} > 0 \Leftrightarrow y^{(i)}(\omega^{\top}x^{(i)} + b) = 0\), i.e. the support vectors, and \(\alpha_{i}=0 \Leftrightarrow y^{(i)} (\omega^{\top} x^{(i)} + b) < 1\) for the others.
The fourth KKT condition \(y^{(i)} (\omega^{\top} x^{(i)} + b) \leq 1\) is satisfied by our construction of the Lagrangian.
The fifth KKT condition \(\alpha_{i} \geq 0\) is satisfied as of our dual optimization problem formulation.
The two then play together in the following fashion:
The dual problem gives \(\alpha^{\star}\)
The primal problem gives \(\omega^{\star}\), \(b^{\star}\), with \(b^{\star}\) given by
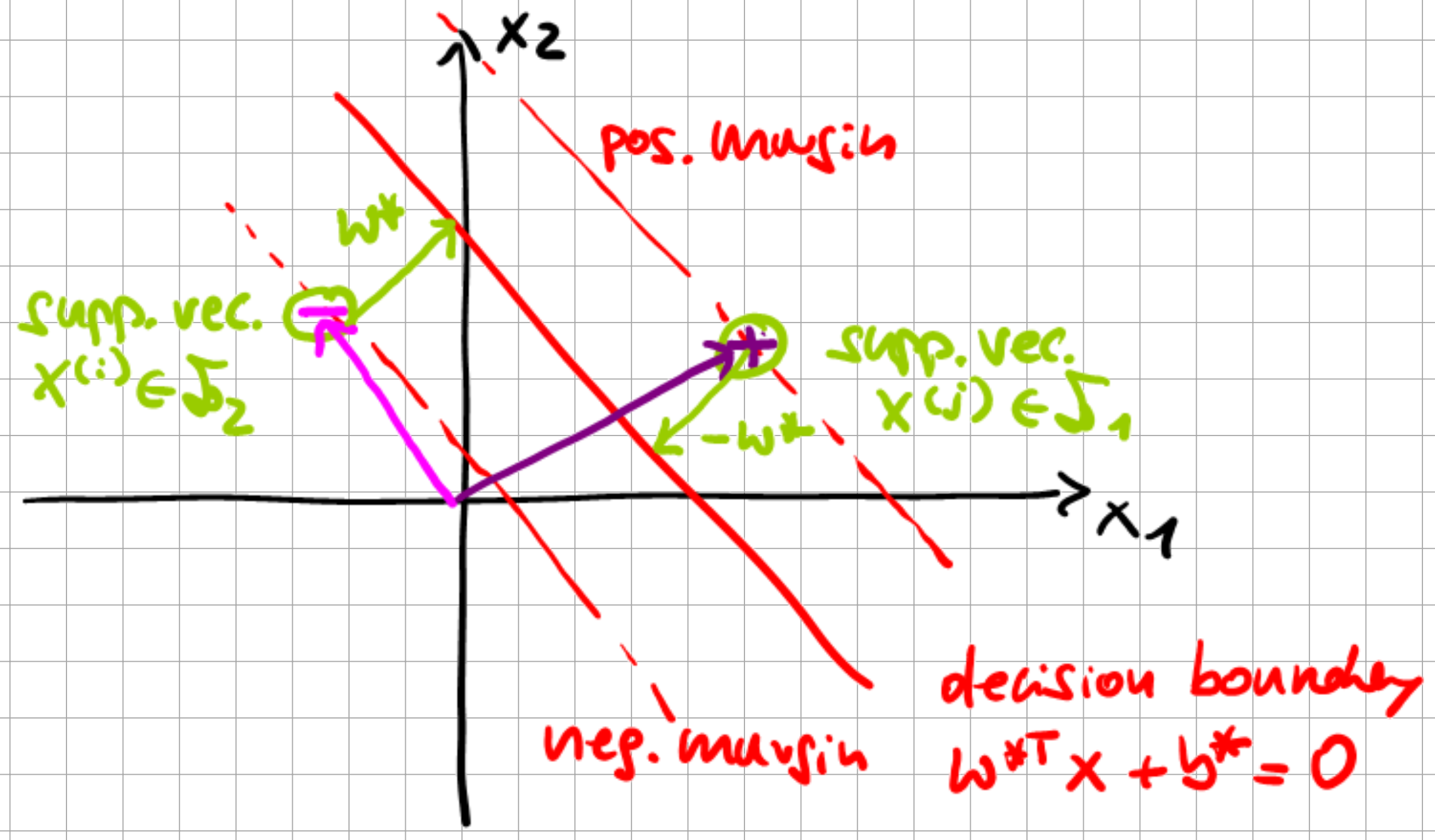
Fig. 6.6 Maximum Margin Classifier solution.#
To derive \(b^{\star}\), we start from \(x^{(i)}\) on the negative margin. One then gets to the decision boundary by \(x^{(i)} + \omega^{\star}\), and from \(x^{(j)}\) on the positive margin by \(x^{(j)} - \omega^{\star}\), i.e.
As \(\omega^{\star^\top} \omega^{\star} = 1\), we can then solve for \(b^{\star}\) and obtain the result in Eq. (6.33). Now we can check how the SVM predicts \(y\) given \(x\):
where \(\alpha_{i}\) is only non-zero for support vectors and calls the inner product \(\langle x^{(i)}, x \rangle\), which is hence a highly efficient computation. We have derived the support vector machine for the linear classification of sets. The formulation of the optimal set-boundary/decision boundary was formulated as the search for a margin optimization, then transformed into a convex, constrained optimization problem before restricting the contributions of the computation to contributions coming from the support vectors, i.e., vectors on the actual decision boundary estimate hence leading to a strong reduction of the problem dimensionality.
6.3. Advanced Topics: Soft Margin Classifier (SMC)#
What if the data is not linearly separable?
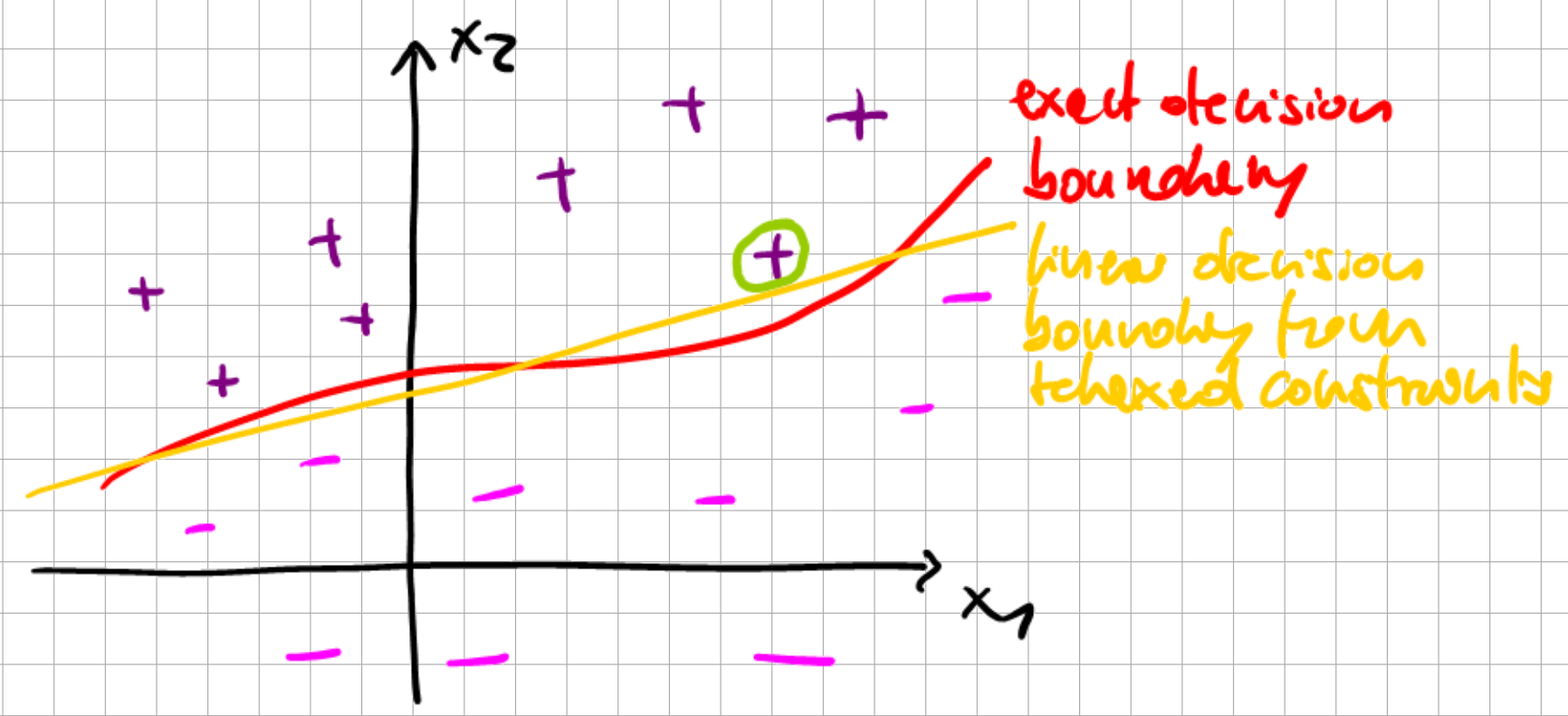
Fig. 6.7 Non-linearly separable sets.#
Data may not be exactly linearly separable, or some data outliers may undesirably deform the exact decision boundary.
6.3.1. Outlier problem#
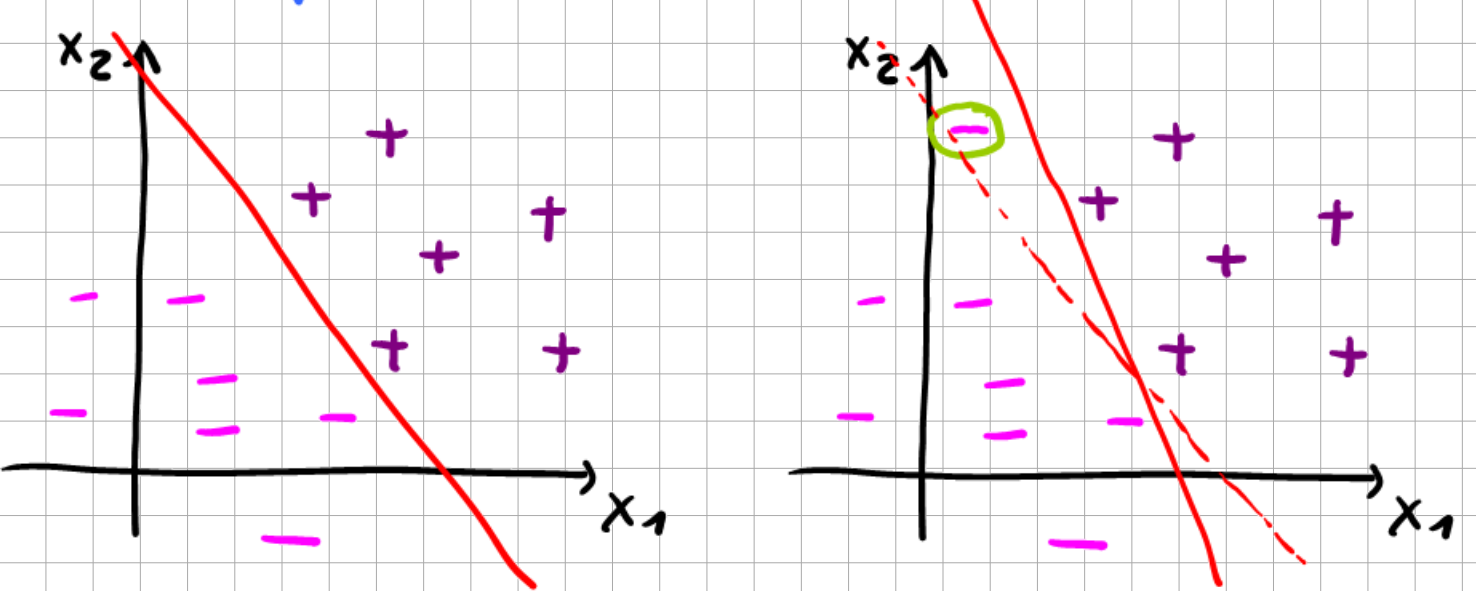
Fig. 6.8 Sensitivity of MMC to outliers.#
6.3.2. Original SVM optimization problem#
To make the algorithm work for non-linearly separable data, we introduce \(l_1\)-regularization, i.e., a penalty term proportional to the magnitude of a certain quantity.
\(\Rightarrow l_1\)-regularised primal optimization problem
Here, \(\xi_i\) is called a “slack” variable. We relax the previous requirement of a unit functional margin \(\hat{\gamma}=1\) by allowing some violation, which is penalized in the objective function.
margin \(\hat{\gamma}^{(i)}=1 - \xi_{i}, \quad \xi_{i}>0\)
penalization \(C\xi_{i}\)
parameter \(C\) controls the weight of the penalization
Then, the Lagrangian of the penalized optimization problem becomes
In the above equation, the second term (\(C \sum_{i=1}^{m} \xi_{i}\)) represents the soft penalization of strict margin violation, whereas the third and fourth terms are the inequality constraints with Lagrangian multipliers \(\alpha_{i}\) and \(\mu_{i}\). The derivation of the dual problem follows from the analogous steps of the non-regularised SVM problem.
The last equation arises from the additional condition due to slack variables. Upon inserting these conditions into \(\mathcal{L}(\omega,b,\xi,\alpha,\mu)\) we obtain the dual-problem Lagrangian:
The “box constraints” (\(0 \leq \alpha_{i} \leq C\)) follow from the positivity requirement on Lagrange multipliers: \(\alpha_{i}\ge 0,\mu_{i}\ge 0\). Evaluating the KKT3-complementarity condition leads to
The resulting dual complementarity conditions for determining the support vectors become:
Support vectors on slack margin (\(\alpha_i=0\), i.e. data point is ignored)
Support vectors inside or outside margin (\(\alpha^*=C\), i.e. data point violates the MMC)
Support vectors on margin (\(\alpha_i^*>0\) & \(\xi_i>0\), i.e. data point on the margin)
The optimal \(b^*\) is obtained from averaging over all support vectors: condition to be satisfied by \(b^*\) is given by SVs on the margin:
\(\Rightarrow\) for \(\omega^*\), we obtain the same result as for the linearly separable problem
For \(b^{\star}\) we then get the condition
A numerically stable option is to average over \(m_{\Sigma}\), i.e. all SV on the margin satisfying \(0<\alpha_{i}^{*}<C\):
Recall: only data with \(\alpha_{i}^*\ne 0\), i.e., support vectors, will contribute to the SVM prediction (last eq. of Maximum Margin Classifier).
In conclusion, we illustrate the functionality of the slack variables.
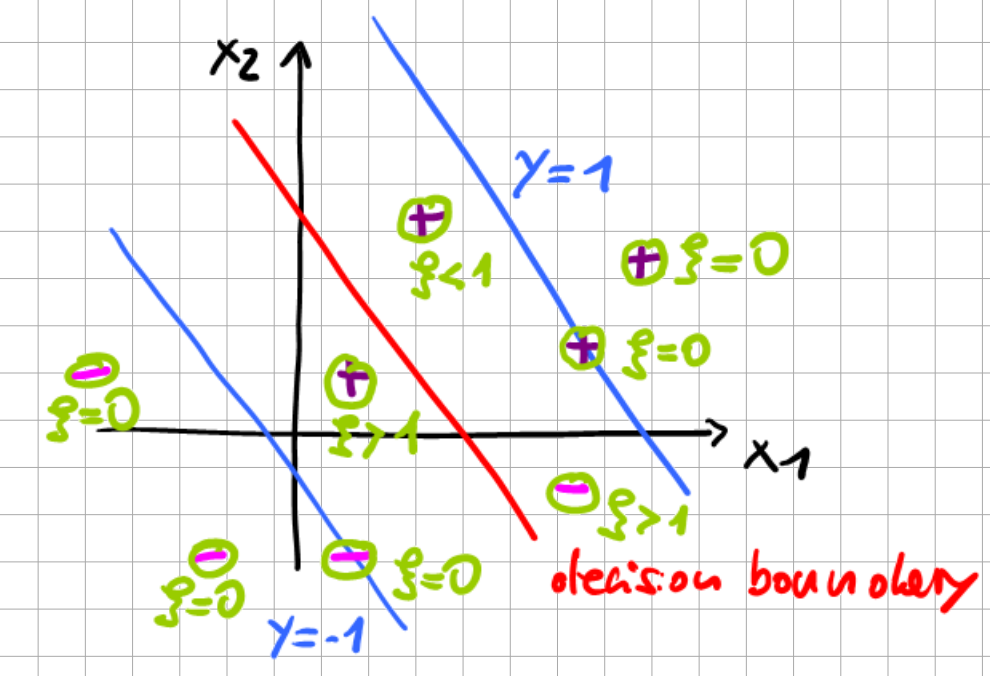
Fig. 6.9 Soft Margin Classifier.#
6.4. Advanced Topics: Sequential Minimal Optimization (SMO)#
Efficient algorithm for solving the SVM dual problem
Based on Coordinate Ascent algorithm.
6.4.1. Coordinate Ascent#
Task : find \(\max _{x} f\left(x_{1}, \ldots, x_{m}\right)\)
Perform a component-wise search on \(x\)
Algorithm
do until converged
for \(i=1, \ldots, m\)
\(\qquad x_{i}^{(k+1)}=\underset{\tilde{x}_{i}}{\operatorname{argmax} } f\left(x_{1}^{(k)}, \ldots, \tilde{x}_{i}, \ldots, x_{m}^{(k)}\right) \)
end for
end do
Sketch of algorithm
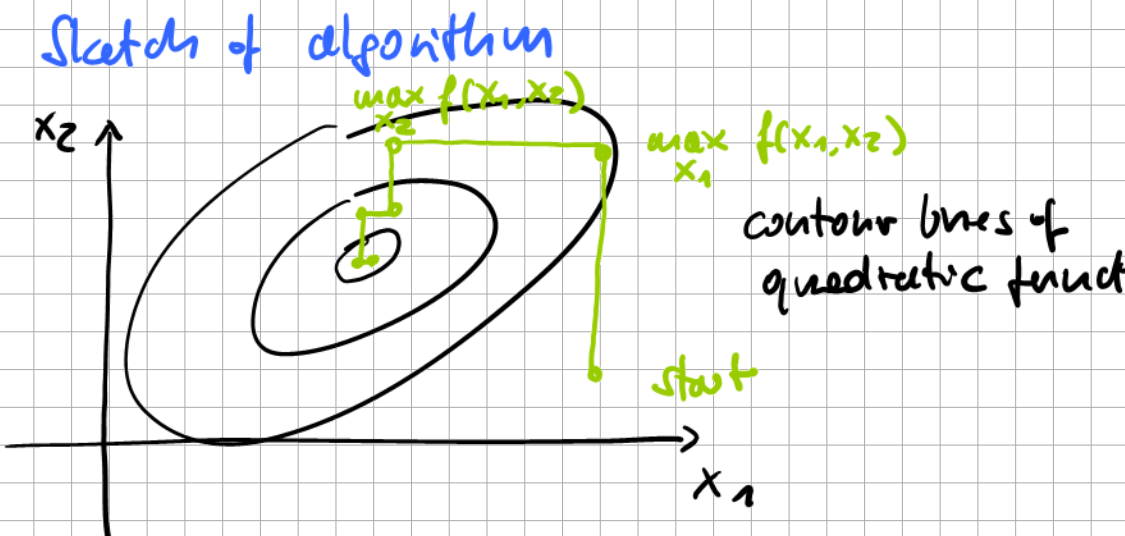
Fig. 6.10 Sequential Minimal Optimization.#
Coordinate ascent converges for convex continuous functions but may not converge to the dual optimum!
6.4.2. Outline of SMO for SVM#
Task: solve SVM dual optimization problem
Consider now an iterative update for finding the optimum:
Iteration step delivers a constraint satisfying set of \(\alpha_{i}\).
Can we just change some \(\alpha_{j} \epsilon\) {\(\alpha_{1}\),….,\(\alpha_{m}\)} according to coordinate ascent for finding the next iteration update?
No, because \(\sum_{i=1}^{m} \alpha_{i}y^{(i)}=0\) constrains the sum of all \(\alpha_{i}\), and varying only a single \(\alpha_{p}\) may lead to constraint violation
Fix it by changing a pair of \(\alpha_{p},\alpha_{q}\) , \(p\ne q\) , simultaneously.
\(\Rightarrow\) the SMO algorithm.
Algorithm
do until convergence criterion satisfied
Given \(\alpha^{(k)}\) constraint satisfying
Select \(\alpha_{p}^{(k+1)}=\alpha_{p}^{(k)}, \; \alpha_{q}^{(k+1)}=\alpha_{q}^{(k)}\) for \(p \ne q\) following some estimate which \(p,q\) will give fastest ascent
Find \(\left(\alpha_{p}^{(k+1)}, \alpha_{q}^{(k+1)}\right)=\underset{\alpha_{p},\alpha_{q}}{\operatorname{argmax} } \theta_{D}\left(x_{1}^{(k)}, \ldots, \alpha_{p}, \ldots,\alpha_{q}, \ldots, x_{m}^{(k)}\right)\) // except for \(\alpha_{p},\alpha_{q}\) all others are kept fixed.
end do
Convergence criterion for SMO: check whether KKT conditions are satisfied up to a chosen tolerance.
Discussion of SMO
assume \(\alpha^{(k)}\) given with \(\sum_{i=1}^{m} y^{(i)} \alpha^{(k)}_{i}=0\)
pick \(\alpha_{1}=\alpha^{(k)}_1\) and \(\alpha_2=\alpha^{(k)}_2\) for optimization
Note that the r.h.s. is constant during the current iteration step.
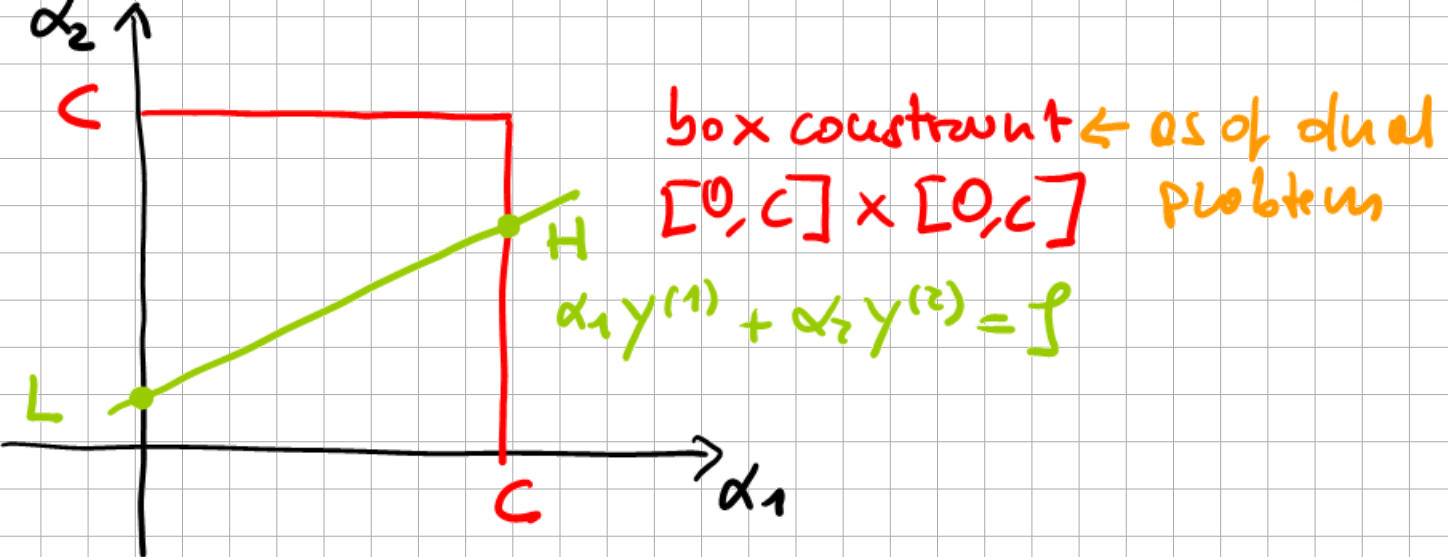
Fig. 6.11 Truncation during Sequential Minimal Optimization.#
The box constraints imply \(L \le \alpha_{2} \le H\). Note that depending on the slope of the line, L or H may be clipped by the box constraint.
\(\alpha_{1} y^{(1)}+\alpha_{2} y^{(2)}=\rho\)
\(\Rightarrow \alpha_{1}=\left(\rho-\alpha_{2} y^{(2)}\right) y^{(1)}\)
\(\rightarrow\) Do you see what happened here?
Answer:
\(\alpha_{1} y^{(1)}+\alpha_{2} y^{(2)}=\rho \quad / \cdot y^{(1)}\)
\(\Rightarrow \alpha_{1} y^{(1)^2}=\left(\rho-\alpha_{2} y^{(2)}\right) y^{(1)}\)
\(y^{(1)^2}=1,\) as \(y \in\{-1,1\}\)
with \(\alpha_{1}=\left(\rho-\alpha_{2} y^{(2)}\right) y^{(1)}\) thus becomes a quadratic function of \(\alpha_2\) , as all other \(\alpha_{j\ne 1,2}\) are fixed.
\(\theta_D(\alpha_2)=A\alpha^2_2+B\alpha_2+const.\) can be solved for \(arg\max_{\alpha_2}\theta_{D}(\alpha_2)=\alpha_2^{'}\)
\(\alpha_2^{'}\rightarrow\) box constraints \(\rightarrow \alpha_2^{''}\)
set \(\alpha_2^{(k+1)} = \alpha_2^{''}\)
next iteration update
6.5. Kernel Methods#
Consider binary classification in the non-linearly-separable case, assuming that there is a feature map \(\varphi(x) \in\mathbb{R}^n\) transforming the input \(x \in\mathbb{R}^d\) to a space which is linearly separable.
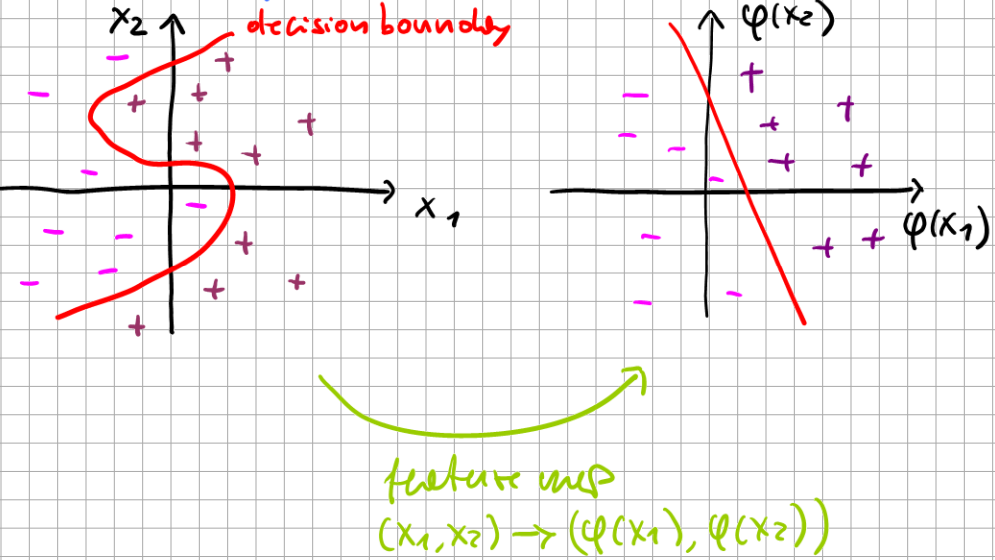
Fig. 6.12 Feature map transformation.#
The feature map is essentially a change of basis as:
In general, \(x\) and \(\varphi\) are vectors where \(\varphi\) has the entire \(x\) as an argument. The resulting modified classifier becomes
Example: XNOR
The following classification problem is non-linear, as there is no linear decision boundary.
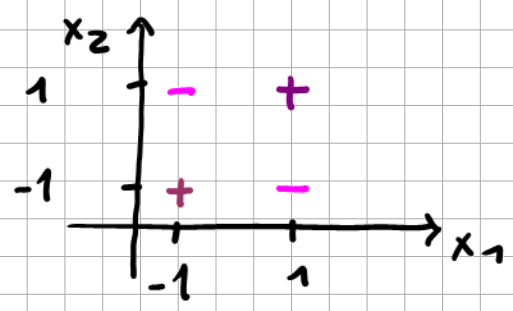
Fig. 6.13 XNOR example.#
Upon defining a feature map \(\varphi (x_1,x_2) = x_1 x_2\) (maps 2D \(\rightarrow\) 1D), we get
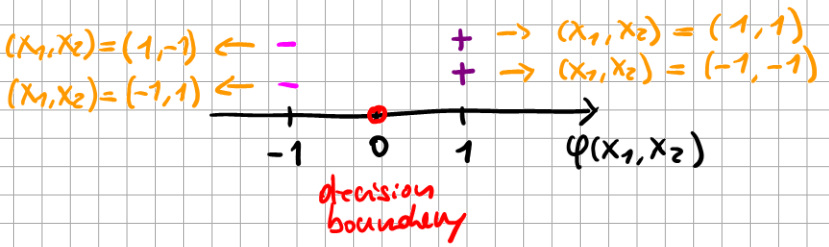
Fig. 6.14 XNOR after feature mapping.#
Example: Circular Region
Given is a set of points \(x \in \mathbb{R}^{2}\) with two possible labels: purple (\(-1\)) and orange (\(1\)), as can be seen in the left figure below. The task is to find a feature map such that a linear classifier can perfectly separate the two sets.
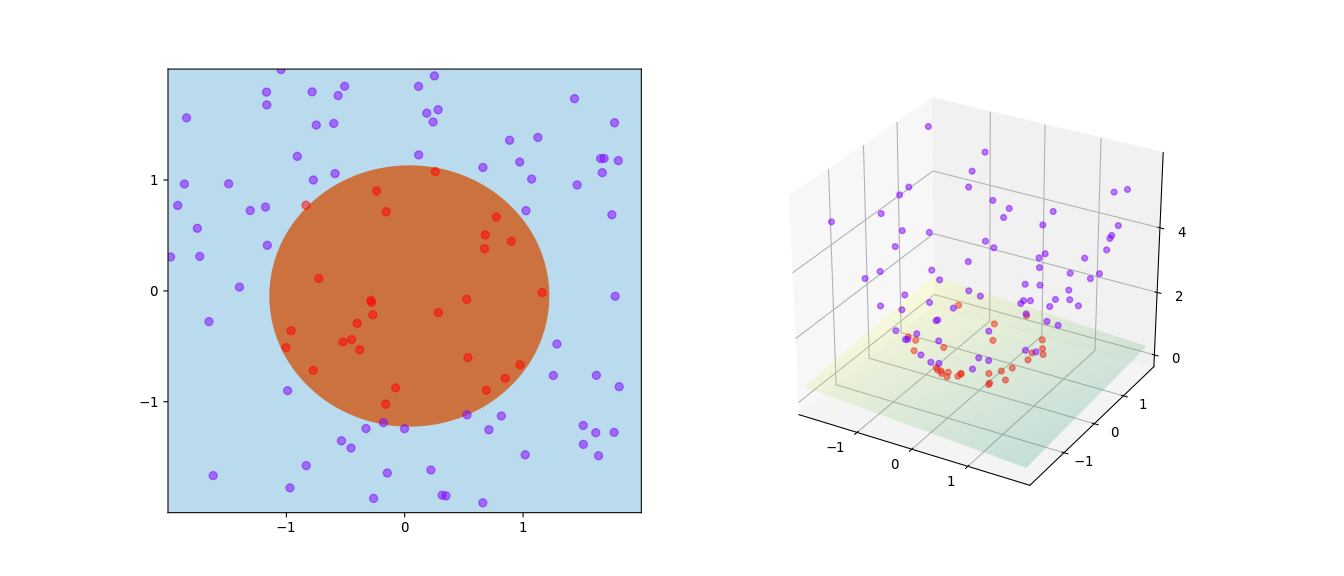
Fig. 6.15 Binary classification of a circular region (Source: Wikipedia).#
Here, it is again obvious that if we embed the inputs in a 3D space by adding their squares, i.e., \(\varphi((x_1, x_2)) = (x_1, x_2, x_1^2+x_2^2)\), we will be able to draw a hyperplane separating the subsets.
But of course, these examples are constructed, as here we could immediately guess \(\varphi(x_1,x_2)\). In general, this is not possible.
Recall: the dual problem of SVM involves a scalar product \(x^{(i)\top}x^{(j)}\) of feature vectors. \(\Rightarrow\) motivates the general notation of a dual problem with feature maps.
6.5.1. Dual representations#
Motivated by Least Mean Squares (LMS) regression, we consider the following regularized cost function:
with penalty parameter \(\lambda \geqslant 0\).
Regularization helps to suppress the overfitting problem (see Tricks of Optimization). The squared L2 regularization above is also called Tikhonov regularization. In machine learning, linear regression in combination with Tikhonov regularization is often dubbed ridge regression.
Setting the gradient of that loss to zero \(\nabla_{\omega}J=0\) we obtain the solution
with design matrix \(\Phi\) using the feature map \(\varphi\) defined as
and
Substituting the necessary condition \(\omega = \Phi^Ta\) into \(J(\omega)\) we obtain the dual problem:
Here, \(K=\Phi\Phi^T\) is a Grammatrix generated by a vector \(\varphi\) according to \(K_{ij} = \langle \varphi_i , \varphi_j \rangle\) where \(\langle \cdot , \cdot \rangle\) is an inner product - here \(\langle \varphi(x^{(i)}),\varphi(x^{(j)}) \rangle\).
where \(K(x^{(i)},x^{(j)})\) is the kernel function.
Now we find that we can express the LMS prediction in terms of the kernel function:
In order to find \(\max_{a} J_D (a)\) we set \(\nabla_a J_D (a) = 0\).
Upon inserting this result into a linear regression model with feature mapping
where \(k_i = K(x^{(i)},x)\) are the components of K.
The kernel trick refers to this formulation of the learning problem, which relies on computing the kernel similarities between a pair of input points \(x\) and \(x'\), instead of computing \(\varphi(x)\) explicitly.
The term Support Vector Machine typically refers to a margin classifier using the kernel formulation.
Now, let’s do some bookkeeping using the number of data points \(M\) and the dimension of the input data \(N\).
Recall from the lecture on linear models that \(\underbrace{\vartheta}_{N}=\underbrace{(X^{T}X)^{-1}}_{N \times N} \underbrace{X^T}_{N \times M} \underbrace{y}_{M}\)
As typically \(M>>N\) we see that solving the dual problem for LMS requires us to invert a \(M\times M\) matrix, whereas the primal problem tends only to a \(N\times N\) matrix.
The benefit of the dual problem with the kernel \(K(x,x')\) is that now we can work with the kernel directly \(\Rightarrow\) dimensionality of \(\varphi(x)\) matters no longer. \(\Rightarrow\) we can consider even an infinite-dimensional feature vector \(N \rightarrow \infty\), i.e. a continuous \(\varphi (x)\)
6.5.2. Construction of suitable kernels#
construction from the feature map
(6.66)#\[ K(x,x') = \varphi^T (x) \varphi (x') = \sum_{i=1}^{N} \varphi_i (x) \varphi_i (x')\]direct construction with the constraint that a valid kernel is obtained, i.e., it actually needs to correspond to a possible feature map scalar product.
A necessary and sufficient condition for a valid kernel is that \(K\) is positive semidefinite for all \(x\).
Example: Kernel 1
Given is \(x, x' \in \mathbb{R}^N\) and a scalar kernel
The corresponding feature map for \(K(x,x') = \varphi^T(x)\varphi(x')\) and with \(N=3\) is
Example: Kernel 2
Alternative kernel with parameter \(c\):
belongs to
Considering that \(\varphi(x)\) and \(\varphi(x')\) are vectors, the scalar product \(K(x,x')=\varphi^T(x)\varphi(x')\) expresses the projection of \(\varphi(x')\) onto \(\varphi(x)\).
\(\Rightarrow\) The larger the kernel value, the more parallel the vectors are. Conversely, the smaller, the more orthogonal they are.
\(\Rightarrow\) Intuitively \(K(x,x')\) is a measure of “how close” \(\varphi(x)\) and \(\varphi(x')\) are.
Example: Gaussian kernel
Now, we illustrate that a valid kernel is positive semidefinite, which is the above-mentioned necessary condition.
6.5.2.1. Proof:#
The necessary and sufficient condition is due to Mercer’s theorem:
A given \(K: \mathbb{R}^N \times \mathbb{R}^N \rightarrow \mathbb{R}\) is a valid kernel if for any {\(x^{(1)},...,x^{(m)}\)}, \(m<\infty\) the resulting \(K\) is positive semidefinite (which implies that it also must be symmetric). We can still apply MMC or slack-variable SMC for non-separable sets: We simply replace the feature-scalar product within the SVM prediction.
We replace \(\langle x^{(i)} , x \rangle\) by \(k(x^{(i)},x)\).
This pulls through into the dual problem for determining \(\alpha_i^*\) and \(b^*\) such that by picking a suitable kernel function, we may get close to a linearly separable transformation function without actually performing the feature mapping.
6.6. Recapitulation of SVMs#
Problem of non-linearly separable sets
Introduction of controlled violations of the strict margin constraints
Introduction of feature maps
Controlled violation: slack variables \(\rightarrow l_1\)-regularized opt. problem \(\rightarrow\) modified dual problem \(\rightarrow\) solution by SMO
Feature map: kernel function (tensorial product of feature maps) \(\rightarrow\) reformulated dual optimization problem \(\rightarrow\) prediction depends only on the kernel function
Kernel construction: a lot of freedom but \(\rightarrow\) valid kernel
Important kernel: Gaussian
Solution of non-separable problems:
Pick a suitable kernel function
Run SVM with a kernel function
6.7. Further References#
[Ng, 2022], Chapters 5 and 6
[Murphy, 2022], Section 17.3
[Bishop, 2006], Appendix E: Lagrange Multipliers